Table of Contents
Introduction
Deep learning models have proven susceptible to adversarial attacks, with gradient-based attacks emerging as particularly effective. Gradient-based attacks are sophisticated exploits that leverage the mathematical underpinnings of ML models and primarily focus on manipulating the optimization processes that are inherent to the learning mechanisms of these models. Given that machine learning models are becoming ubiquitous across various sectors, understanding the intricacies of gradient-based attacks is critical for developing robust security frameworks and protecting the integrity and reliability of ML models.
Understanding Gradient-Based Attacks
Gradient-based attacks refer to a suite of methods employed by adversaries to exploit the vulnerabilities inherent in ML models, focusing particularly on the optimization processes these models utilize to learn and make predictions. These attacks are called “gradient-based” because they primarily exploit the gradients, mathematical entities representing the rate of change of the model’s output with respect to its parameters, computed during the training of ML models. The gradients act as a guide, showing the direction in which the model’s parameters need to be adjusted to minimize the error in its predictions. By manipulating these gradients, attackers can cause the model to misbehave, make incorrect predictions, or, in extreme cases, reveal sensitive information about the training data.
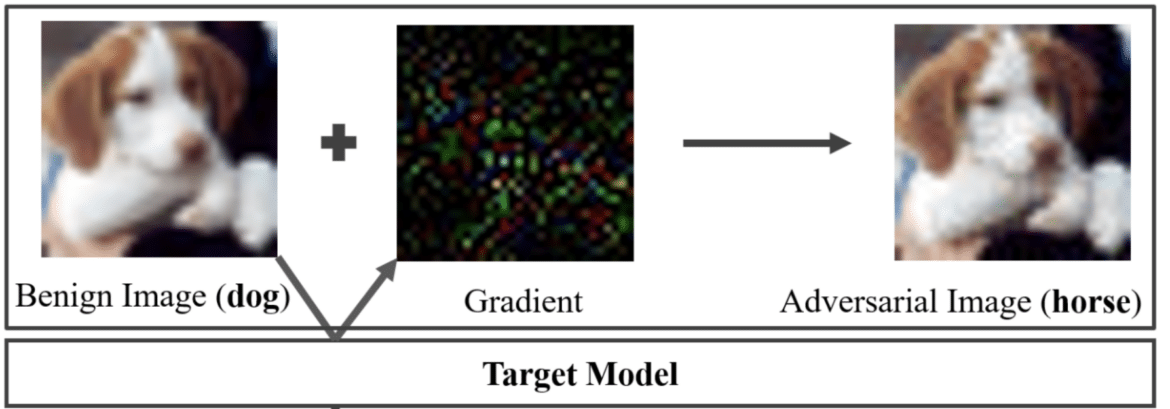
fool the target model, e.g., changing the predicted class from dog
to horse [1]
How Gradient-Based Attacks Work?
Essentially, these attacks revolve around an attacker having varying levels of access to the model’s information and utilizing this access to manipulate the model’s outcomes. The attacker, having knowledge of the model’s architecture, parameters, and training data, can compute gradients to find the optimal input modifications to achieve their malicious objectives, be it causing misclassifications or extracting sensitive information. They exploit the vulnerability of models during the training and inference stages by injecting malicious input or altering the learning process to compromise model integrity and confidentiality.
Types of Gradient-Based Attacks?
Gradient-based attacks can largely be categorized into two types: white-box attacks and black-box attacks. White-box attacks are scenarios where the attacker has complete knowledge and access to the model, including its architecture, parameters, training data, and output. This comprehensive access allows attackers to compute gradients accurately and devise potent attack strategies to compromise the model. The Fast Gradient Sign Method (FGSM) and the Carlini & Wagner (C&W) Attack are prominent examples of white-box gradient-based attacks.
Conversely, in black-box attacks, the attacker has no or very limited knowledge of the model’s internal workings and has access only to the model’s input and output. In this scenario, attackers typically employ techniques like query-based attacks and transfer attacks [2], wherein they craft adversarial examples on surrogate models (or substitute models) on which they perform white-box attacks. The generated adversarial examples are then transferred to the target model, hoping they remain effective. Black-box attacks might be less effective since they rely on the transferability of adversarial examples.
Gradient Based Adversarial Attack Techniques
Fast Sign Gradient Method (FGSM)
The Fast Sign Gradient Method (FGSM) is a popular adversarial attack technique introduced by Goodfellow et al. in 2014 [3]. It is designed to perturb input data in a way that leads machine learning models, especially deep neural networks, to make incorrect predictions. The primary idea behind FGSM is to utilize the gradient of the loss with respect to the input data to create adversarial examples. By doing so, it aims to maximize the loss of the model on the perturbed input, causing the model to misclassify it.
The method works by computing the gradient of the loss function with respect to the input data and then adjusting the input data in the direction of the sign of this gradient. The perturbation is controlled by a parameter which determines the magnitude of the change applied to the input. The perturbed input is then given to the model, which often results in a misclassification.
FGSM is particularly notable because of its simplicity and efficiency. With just a single step, it can generate adversarial examples that can deceive state-of-the-art models. However, it’s worth noting that while FGSM is effective, there are other more sophisticated adversarial attack methods that have been developed since its introduction.
Fast Feature Gradient Sign Method (FFGSM)
The Fast Feature Gradient Sign Method (FFGSM) is an extension of the FGSM [4]. While FGSM focuses on perturbing the input space directly, FFGSM perturbs the feature space of a model, targeting intermediate layers rather than the input layer. This approach can provide a more nuanced way to generate adversarial examples, as it considers the internal representations learned by the model.
The idea behind FFGSM is to compute the gradient of the loss with respect to the features at a specific layer of the model. By perturbing these features in the direction of the gradient sign, the model can be misled into making incorrect predictions.
Iterative Fast Gradient Sign Method (I-FGSM)
The Iterative Fast Gradient Sign Method (I-FGSM) is an extension of the Fast Gradient Sign Method (FGSM), designed to generate adversarial examples through an iterative process. While FGSM introduces a one-step perturbation to the input data based on the gradient of the loss function, I-FGSM refines this approach by applying multiple small perturbations in an iterative manner. This iterative process allows for a more fine-tuned search in the input space, often leading to the generation of more potent adversarial examples.
Introduced by Kurakin et al. in 2016 [5], I-FGSM starts with an initial adversarial example and iteratively applies the FGSM update. At each step, the perturbation is clipped to ensure that the adversarial example remains within a specified ε-bound of the original input. This iterative approach allows the method to navigate around potential defenses or gradient masking techniques that might thwart a one-step attack like FGSM.
I-FGSM has been shown to produce adversarial examples that are more effective in fooling deep neural networks compared to FGSM, especially when models employ certain defensive mechanisms.
Momentum Iterative Fast Gradient Sign Method (MI-FGSM)
The Momentum Iterative Fast Gradient Sign Method (MI-FGSM) is an enhanced adversarial attack technique that builds upon the foundational Fast Gradient Sign Method (FGSM). Introduced by Dong et al. in 2017 [6], MI-FGSM incorporates momentum into the iterative FGSM process to stabilize update directions and escape from poor local maxima. This results in the generation of more transferable adversarial examples, which are effective against a wider range of models.
The primary motivation behind MI-FGSM is to address the limitation of FGSM and its iterative variant (I-FGSM) in producing adversarial examples that transfer well across different models. By incorporating momentum, MI-FGSM accumulates the gradient of the loss from previous steps, which guides the adversarial perturbation in a more consistent direction. This consistent direction helps in generating adversarial examples that are not only effective against the targeted model but also against other models, enhancing the transferability of the attack.
MI-FGSM has been shown to be particularly effective in black-box attack settings, where the attacker does not have direct access to the target model’s architecture or weights but aims to generate adversarial examples that can fool it.
Projected Gradient Descent (PGD)
The Projected Gradient Descent (PGD) is an iterative optimization technique that seeks to find the most adversarial perturbation within a predefined constraint set. This method is particularly notable for its robustness and its ability to generate adversarial examples that can fool even well-defended models.
Introduced by Madry et al. in 2017 [7], PGD operates by starting from a random point within the allowed perturbation region of the original input. It then performs gradient descent on the model’s loss function, projecting the perturbed input back into the feasible set after each iteration. This iterative process ensures that the adversarial perturbation remains within the defined constraints around the original input, making the adversarial example both effective and imperceptibly different to human observers.
Carlini & Wagner (C&W) Attack
The Carlini & Wagner (C&W) Attack is a sophisticated gradient-based adversarial attack method developed by Nicholas Carlini and David Wagner in 2017 [8]. This attack is designed to craft adversarial examples that can effectively fool deep neural networks while ensuring the perturbations are minimal and imperceptible. Among the various norms that can be used to measure the perturbation magnitude, the L2 norm-based variant of the C&W attack is particularly notable for its effectiveness and precision.
The C&W attack with L2 norm seeks to solve an optimization problem where the objective is to find the smallest L2 norm perturbation that can lead the model to misclassify the input. The attack introduces a change to the input data by minimizing a combination of two terms: the L2 distance between the original and perturbed input, and a term that ensures the perturbed input is misclassified.
The C&W L2 attack is known for its robustness, often succeeding where other attacks fail. It has been shown to produce adversarial examples that can bypass various defense mechanisms.
Targets of Gradient-Based Attacks
Regarding the targets of gradient-based attacks, virtually no models and systems are exempt from vulnerability. From linear models to complex deep neural networks [9], all machine learning models are susceptible to these attacks due to their reliance on gradient-based optimization during training. However, the degree of susceptibility may vary depending on the model’s complexity, training data, and employed defenses. The increasing reliance on machine learning across diverse applications like healthcare, finance, and autonomous vehicles accentuates the urgency to comprehend and mitigate the vulnerabilities and risks associated with gradient-based attacks.
Machine Learning Models & Their Vulnerabilities
ML models, the cornerstone of AI applications, encompass a variety of structures, from linear regressions to advanced deep learning networks, each designed to identify patterns in data and make autonomous predictions. However, their dependency on data and adaptive nature renders them susceptible to numerous inherent vulnerabilities, often exploited through gradient-based attacks, causing models to deliver incorrect outputs or reveal sensitive information. The process of optimization, essential for refining models, is especially critical as it involves the computation of gradients to minimize errors, making it a focal point for adversaries aiming to manipulate model behavior by altering this process. Numerous instances exist where varying model architectures like deep neural networks and support vector machines have been exploited, with attackers employing techniques like adversarial attacks and model inversion, demonstrating the omnipresent vulnerabilities and emphasizing the critical need for robust defense strategies in ML models.
Optimization Exploits
The optimization process in machine learning models is a fertile ground for various exploits, particularly in the context of gradient-based attacks. Optimization, a central process in model training aimed at minimizing errors through parameter adjustments, is manipulated by attackers to alter model behavior or to glean confidential information. Numerous methodologies are employed by attackers to exploit optimization, including generating adversarial examples that force models into making incorrect predictions and conducting model inversion attacks to reveal sensitive training data. The potential damage ensuing from these exploits is extensive, ranging from undermining model integrity and causing significant financial and reputational losses to organizations to violating user privacy by exposing confidential information. The real-world implications and manifestations of such exploits are vast, with instances like evasion attacks on cybersecurity models causing them to overlook malicious activities and the exploitation of recommendation systems leading to manipulated content being propagated to users, underscoring the imperative nature of understanding and mitigating optimization exploits in securing machine learning models.
Mitigation and Defense Strategies
Importance of Security in Machine Learning
The deployment of ML models in sensitive domains like healthcare, finance, and even national security and defence means that any compromise can have severe, far-reaching consequences, including the loss of sensitive information, financial losses, and degradation of user trust. Thus, the importance of security in machine learning models cannot be overstated, as it ensures the integrity, availability, and confidentiality of the information processed by these models.
Defensive Measures
Defensive measures against gradient-based attacks are multifaceted, aiming to fortify models against various vulnerabilities. These include adversarial training [10], where models are trained with adversarial examples to enhance their resilience against malicious inputs. Defensive distillation is another technique where models are trained to generalize learning from a previously trained model, reducing the sensitivity to the input data changes. Additionally, employing robustness against evasion attacks and incorporating model-hardening strategies is paramount. Regular updates and patches, constant monitoring, and immediate response to any identified vulnerabilities are also critical components of a robust defense strategy.
Best Practices
Securing ML models against gradient-based attacks necessitates the adoption of best practices in model development, deployment, and maintenance. These include meticulous validation and verification of models to ensure they behave as expected under various conditions and incorporating security considerations from the early stages of model development. Employing encryption and robust access controls is also vital in safeguarding models and their associated data. Additionally, fostering a security-centric culture within organizations and continuously educating development and operational teams about the evolving threat landscape contribute to building a solid foundation for ML model security.
Future Developments
The dynamic and continually evolving landscape of ML model security necessitates constant innovation and development in defensive measures. The future is likely to see the emergence of more sophisticated defense mechanisms driven by advancements in ML and cybersecurity research. The integration of AI and ML in developing adaptive and intelligent defense systems is expected to play a significant role in identifying and mitigating novel attack vectors. Furthermore, the development of standardized security protocols and frameworks, along with collaborative efforts between academia, industry, and regulatory bodies, will be crucial in establishing comprehensive and resilient defense strategies against the multifarious threats targeting ML models.
Recent Research on Gradient-Based Attacks
Recent advancements in research have painted a comprehensive picture of the landscape of gradient-based attacks. For instance, a study in [11] illuminated the vulnerabilities in neural networks, showcasing how these models misinterpret the input data. Subsequent research [12] looked deeper into the adversarial settings in deep learning, providing insight into potential defense mechanisms. Additionally, [13] presented a meticulous examination of the robustness of neural networks, offering a fresh perspective on attack methodologies. In a more targeted approach, a study [14] provided a compelling discourse on the circumvention of defenses in adversarial examples. Lastly, research [15] contributed to the dialogue by focusing on the effectiveness of adversarial training under gradient diversity regularization. These seminal works collectively accentuate the ongoing advancements and the multifaceted nature of research in the realm of gradient-based attacks, guiding the development of more robust and resilient machine-learning models.
Conclusion
Gradient-based attacks epitomize the intersection of optimization exploits and machine learning vulnerabilities, representing a significant challenge. The complex tapestry of these attacks, ranging from white-box to black-box attacks, underscores the urgent necessity to comprehend and implement robust defense mechanisms to safeguard machine learning models.
References
- Hong, H., Hong, Y., & Kong, Y. (2022). An Eye for an Eye: Defending against Gradient-based Attacks with Gradients.
- Mao, Y., Fu, C., Wang, S., Ji, S., Zhang, X., Liu, Z., … & Wang, T. (2022, May). Transfer attacks revisited: A large-scale empirical study in real computer vision settings. In 2022 IEEE Symposium on Security and Privacy (SP) (pp. 1423-1439). IEEE.
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
- Wong, E., Rice, L., & Kolter, J. Z. (2020). Fast is better than free: Revisiting adversarial training. In International Conference on Learning Representations (ICLR).
- Kurakin, A., Goodfellow, I., & Bengio, S. (2016). Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533.
- Dong, Y., Liao, F., Pang, T., Su, H., Zhu, J., Hu, X., & Li, J. (2017). Boosting adversarial attacks with momentum. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9185-9193).
- Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2017). Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083.
- Carlini, N., & Wagner, D. (2017). Towards evaluating the robustness of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP) (pp. 39-57). IEEE.
- Bassey, J., Qian, L., & Li, X. (2021). A survey of complex-valued neural networks. arXiv preprint arXiv:2101.12249.
- Zhao, W.; Alwidian, S.; Mahmoud, Q.H. Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms 2022, 15, 283. https://doi.org/10.3390/a15080283
- Zhang, J., & Li, C. (2019). Adversarial examples: Opportunities and challenges. IEEE transactions on neural networks and learning systems, 31(7), 2578-2593.
- Papernot, N., McDaniel, P., Jha, S., Fredrikson, M., Celik, Z. B., & Swami, A. (2016, March). The limitations of deep learning in adversarial settings. In 2016 IEEE European symposium on security and privacy (EuroS&P) (pp. 372-387). IEEE.
- Chen, J., Wu, X., Guo, Y., Liang, Y., & Jha, S. (2021). Towards evaluating the robustness of neural networks learned by transduction. arXiv preprint arXiv:2110.14735.
- Athalye, A., Carlini, N., & Wagner, D. (2018, July). Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International conference on machine learning (pp. 274-283). PMLR.
- Lee, S., Kim, H., & Lee, J. (2022). Graddiv: Adversarial robustness of randomized neural networks via gradient diversity regularization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2), 2645-2651.
For 30+ years, I've been committed to protecting people, businesses, and the environment from the physical harm caused by cyber-kinetic threats, blending cybersecurity strategies and resilience and safety measures. Lately, my worries have grown due to the rapid, complex advancements in Artificial Intelligence (AI). Having observed AI's progression for two decades and penned a book on its future, I see it as a unique and escalating threat, especially when applied to military systems, disinformation, or integrated into critical infrastructure like 5G networks or smart grids. More about me, and about Defence.AI.